现在有很多网站,已经能够通过JA3或者其他指纹信息,来识别你的请求是不是Requests发起的。这种情况下,你无论怎么改Headers还是代理,都没有任何意义。
我之前写过一篇文章:Python如何突破JA3,但方法非常复杂,很多初学者表示上手有难度。那么今天我来一个更简单的方法,只需要修改两行代码。并且不仅能过JA3,还能过Akamai。
先来看一段代码:
```pythonimport requests headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'cache-control': 'no-cache', 'dnt': '1', 'pragma': 'no-cache', 'sec-ch-ua': '"Chromium";v="118", "Microsoft Edge";v="118", "Not=A?Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'same-origin', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.46', } response = requests.get('https://tls.browserleaks.com/json', headers=headers) print(response.json()) 运行效果如下图所示: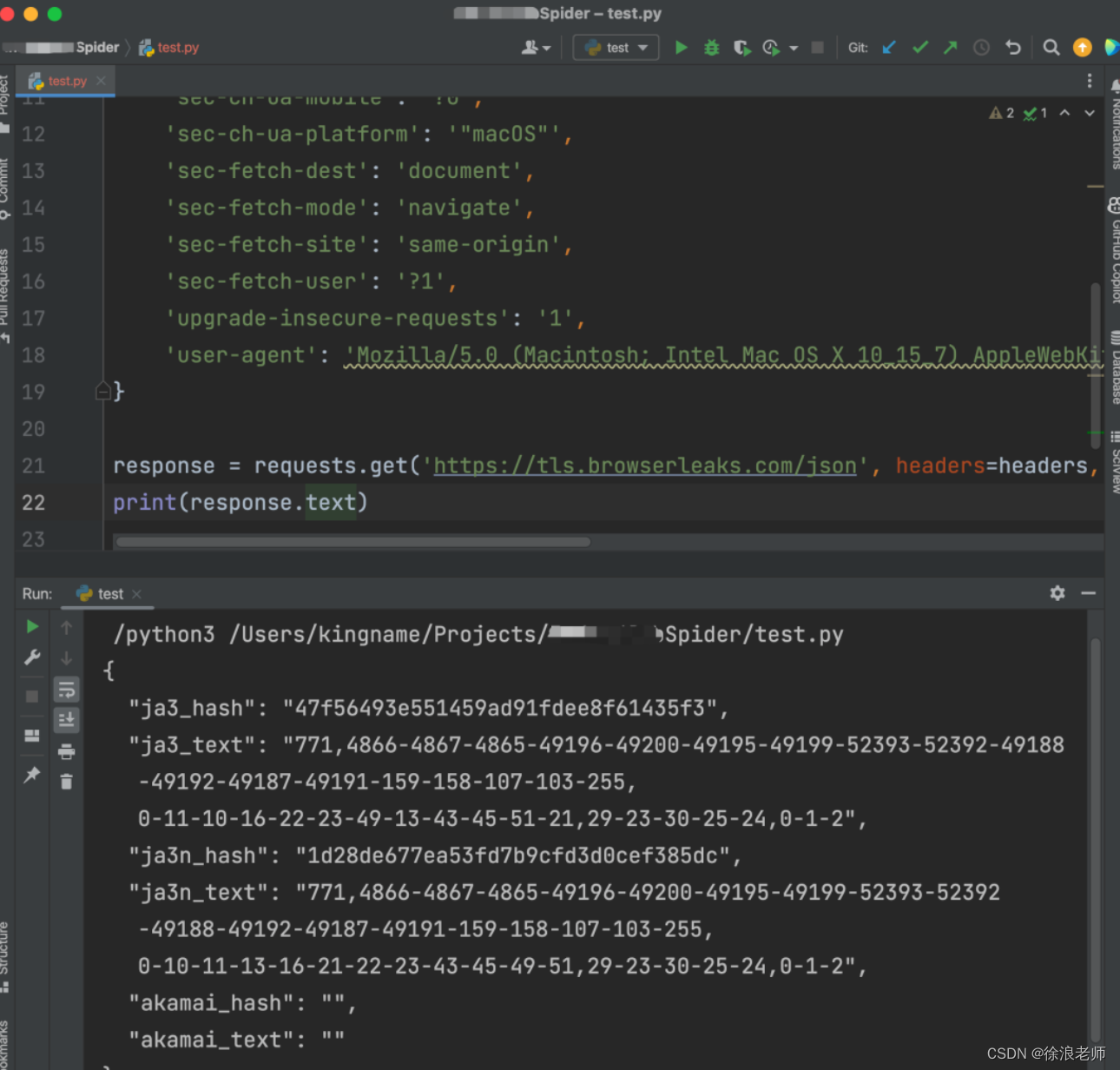## 整体架构流程` 提示:这里可以添加技术整体架构`这是直接使用Requests发起的请求。你可以试一试,加上代理以后,这里的ja3_hash并不会发生变化。并且akamai_hash和akamai_text都是空。这个特征是非常明显的,网站直接根据这些特征就可以屏蔽你的爬虫。现在,我们使用两行代码解决这个问题。首先,安装一个第三方库:curl_cffi:python3 -m pip install curl_cffi然后,修改我们这段代码的第一行,把import requests改成from curl_cffi import requests。最后,在requests.get中加一个参数:impersonate="chrome110"。完整效果如下图所示:## 技术名词解释```pythonimport asynciofrom curl_cffi.requests import AsyncSessionurls = ["https://googel.com/","https://facebook.com/","https://twitter.com/",]async def main():async with AsyncSession() as s:tasks = []for url in urls:task = s.get("https://example.com")tasks.append(task)results = await asyncio.gather(*tasks)asyncio.run(main()) 技术细节完成了。以上就是全部修改。网站已经无法识别你的爬虫了。在网站看来,这只是一个Chrome 110版本发起的请求。甚至Akamai需要的签名也都有了。
curl_cffi不仅完全兼容Requests的语法,而且还支持Asyncio。要使用异步写法时,代码如下:
小结关于curl_cffi的更多用法,可以查看它的Github:Python binding for curl-impersonate via cffi[1]

